So much has changed in the last few decades, particularly in terms of digitization, in the ways historians access materials, the level and ease of access to those materials, and the methods of delivery for the work that comes from that access. But access is not the only thing that has changed. Working in the digital realm offers historians new tools with which to approach their task, the core of which remains unaffected by these developments. On that theme, I thought I would talk a little bit about my workflow and the tools that I use which allow the work to flow (sorry, couldn’t help myself).
Most historians use a word processor and many use some kind of citation management software. For years, it seems that EndNote was the most widely used for this purpose. I used it as well until about three years ago when I switched from PC to Mac. That move was done primarily because I wanted to use two pieces of software which were not then available for PC, though both are now.
 The first is Mekentosj’s Papers. Think of Papers as an iTunes for your PDFs (but better). I don’t know about most people but I am an obsessive collector of PDFs. I download articles from JSTOR if I think I might ever need them sometime in the distant future. I also regularly scan book chapters. I currently have over 3,500 PDFs on my hard drive. Papers allows me to keep them all organized, sorted into thematic “collections,” and, for most journal articles, it can automatically fill-in the citation information (click on pictures for larger view). You can take notes on your PDFs, comment on them, and highlight them (and the quotes you highlight appear in your Notes tab). It also creates an OCR text file that is kept separate from the actual PDF but is used when you run full-text searches. You can also search JSTOR and a number of databases for journal articles and import them into your library right from within the application.
The first is Mekentosj’s Papers. Think of Papers as an iTunes for your PDFs (but better). I don’t know about most people but I am an obsessive collector of PDFs. I download articles from JSTOR if I think I might ever need them sometime in the distant future. I also regularly scan book chapters. I currently have over 3,500 PDFs on my hard drive. Papers allows me to keep them all organized, sorted into thematic “collections,” and, for most journal articles, it can automatically fill-in the citation information (click on pictures for larger view). You can take notes on your PDFs, comment on them, and highlight them (and the quotes you highlight appear in your Notes tab). It also creates an OCR text file that is kept separate from the actual PDF but is used when you run full-text searches. You can also search JSTOR and a number of databases for journal articles and import them into your library right from within the application.
Papers also recently added the citation management features of EndNote. So you can also search Google Books and the Library of Congress and import entries for books right from within. You can add citations to your papers either through a shortcut-enabled search window or simply by dragging the entry from your library onto your Word document. For each of my projects, I create a collection on the left sidebar and when I need to create a bibliography I simply highlight all the entries in the collection and drag them onto my document and the bibliography is done. For me, the process is much quicker and more intuitive than EndNote, which still looks like a late-1990s Windows program. It also has an iPhone/iPad app that allows for syncing your entire library or just specific collections so you can have your PDFs available on your device as well.
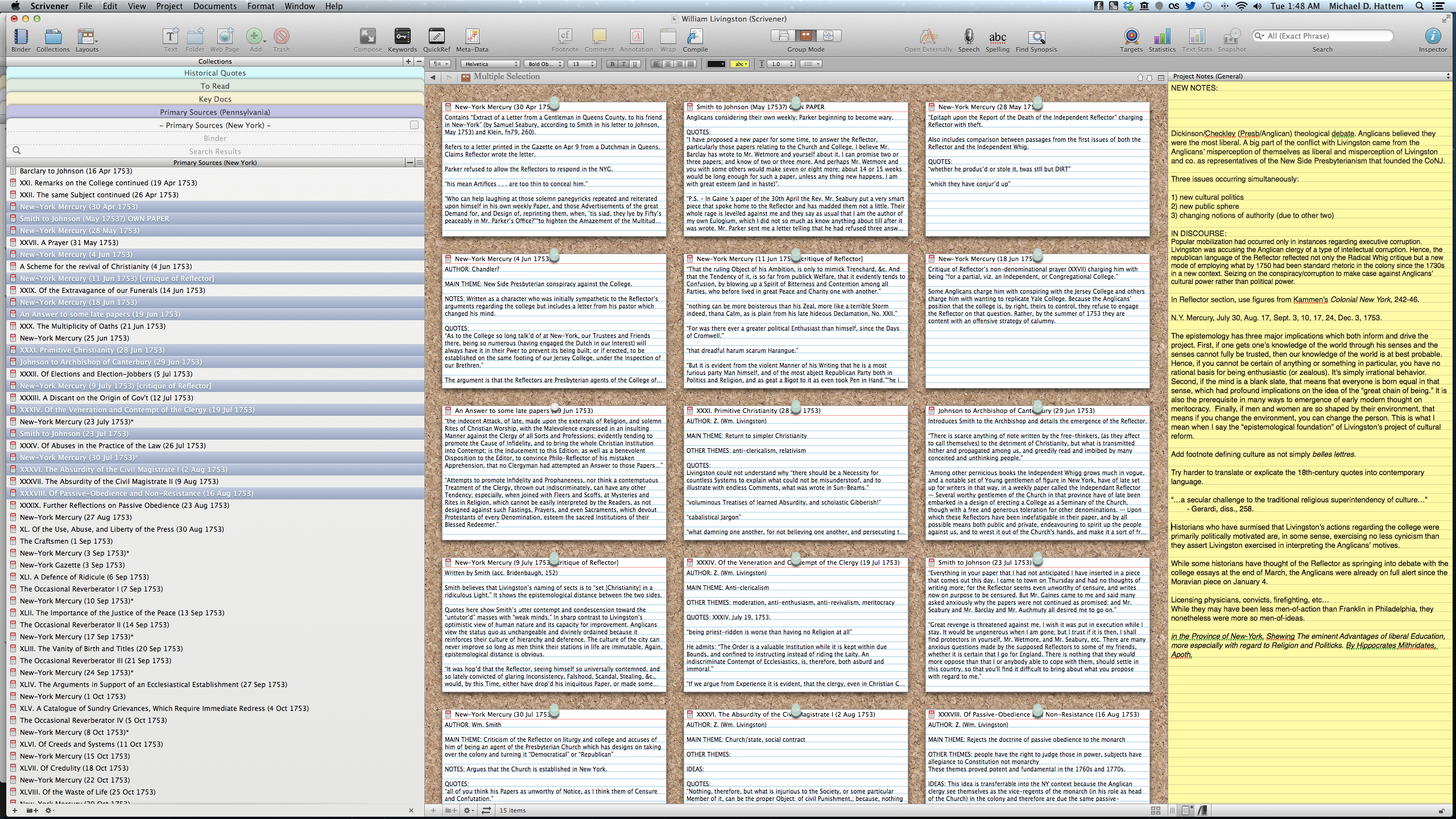
 The second application that I use, and the most important, is a writing app called Scrivener. It would take a series of posts to fully describe everything this application can do. Originally conceived for novelists and scriptwriters, I have customized it to be used for historical research and writing. As you can see from the pictures, on the left side of the screen is your “Binder.” Here is where you keep all your documents. Into the “Research” folder, I import all my relevant PDFs and sort them into two large folders, Primary and Secondary, and then into subfolders for each theme or topic in the paper. Each document gets its own “legal pad-esque” Notes section and each can be tagged and labeled in numerous ways. You can even import web pages and view them within the application.
The second application that I use, and the most important, is a writing app called Scrivener. It would take a series of posts to fully describe everything this application can do. Originally conceived for novelists and scriptwriters, I have customized it to be used for historical research and writing. As you can see from the pictures, on the left side of the screen is your “Binder.” Here is where you keep all your documents. Into the “Research” folder, I import all my relevant PDFs and sort them into two large folders, Primary and Secondary, and then into subfolders for each theme or topic in the paper. Each document gets its own “legal pad-esque” Notes section and each can be tagged and labeled in numerous ways. You can even import web pages and view them within the application.
In the “Essay” folder at the top are the text documents in which I am writing the actual paper. Scrivener’s split-screen means I can have a document in one window while writing in the other. Or I can use it to easily compare two documents, instead of opening up two Preview windows. In my Essay folder, I create documents and subdocuments for each part of the paper that acts as an outline and also lets me focus on just the section on which I am working. Scrivener also has a feature called “Collections” in which you can place documents from your Binder. As you can see in the picture, for this project, I put all my primary sources into one collection and then 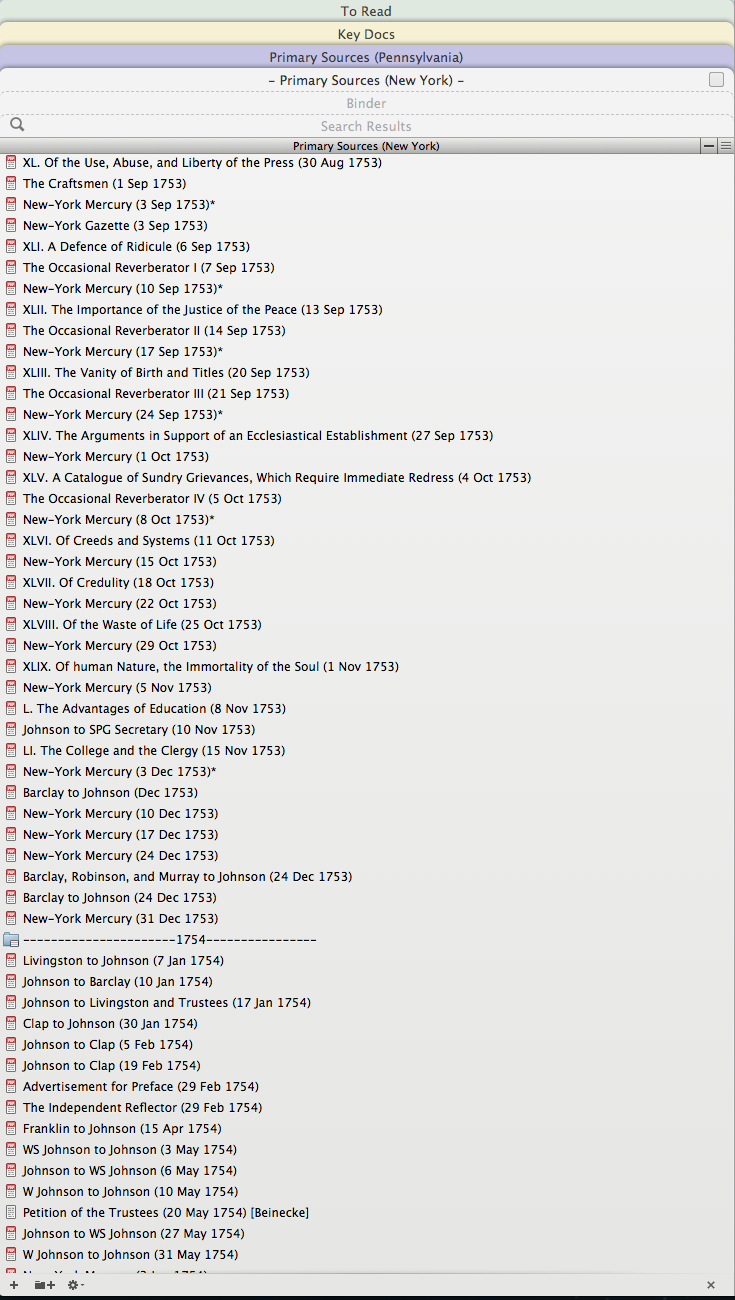 ordered them chronologically, which allowed me to follow the newspaper/pamphlet debates as they would have appeared to an interested reader but also includes PDF scans of chronologically-ordered correspondence.
ordered them chronologically, which allowed me to follow the newspaper/pamphlet debates as they would have appeared to an interested reader but also includes PDF scans of chronologically-ordered correspondence.
For those not ready to completely give up old tried-and-true methods, Scrivener also has an index card feature. Every document—PDF or text—gets its own index card which shows up in the inspector pane on the right. But you can also see your index cards on a corkboard and order them as you like. Scrivener also allows you to import picture and audio files, so you can import all the JPGs you take on an archives trip. I also create folders in which I keep random notes and ideas as well as previous drafts of the paper. Essentially, Scrivener allows me to have almost all of my research easily and instantly accessible in the same app in which I am writing. The best part is that it is highly customizable so each user can tailor to their own needs or workflow.
 Once I am done writing, Scrivener exports my paper, formatted in Chicago style, as a Word file. However, about a year ago, I abandoned Microsoft Word for Apple’s Pages. I just found Word to be too bloated with too many quirks. Pages is less cluttered and just much simpler, especially the way it handles footnotes/endnotes. In Pages, I take care of any minor formatting changes if necessary and run the spell-checker and Proofreader. Then I export the final paper to PDF and the process is complete.
Once I am done writing, Scrivener exports my paper, formatted in Chicago style, as a Word file. However, about a year ago, I abandoned Microsoft Word for Apple’s Pages. I just found Word to be too bloated with too many quirks. Pages is less cluttered and just much simpler, especially the way it handles footnotes/endnotes. In Pages, I take care of any minor formatting changes if necessary and run the spell-checker and Proofreader. Then I export the final paper to PDF and the process is complete.
Of course, this is my own personal workflow and I am not suggesting that it is a model for other historians. However, I have obviously found the tools useful in the context of historical research and writing. If you are looking for a way to manage large numbers of documents for a large writing project or simply want to try to shake up your workflow, they provide excellent possibilities. What applications and tools are you currently using for research and writing?
AUTHOR’S NOTE: Both Papers and Scrivener are available for 30-day free trials. Both are available for both Mac and PC.
ADDENDUM: I mentioned in the comments section that I was willing to share my Preferences file, my Chicago Style Compile preset, and my customized project template. I’ve had more than a few persons take me up on that offer. You can email me (see Contributor page) or the blog for instructions and a link to download the files from Dropbox.

This is really interesting stuff, Michael. One thing I wonder – presumably your use of Papers depends rather heavily on your effective and systematic tagging of your PDF files. Do you have any recommendations on how to develop that sort of system?
Dave G’s comment touches on this. However, unlike him, I decided early on that coming up with a standardized tagging system would just take too much time (for 3000+ PDFs). So instead I use the Collections feature. So upon importing a PDF, I immediately put it into the various relevant Collections (both chronological and thematic). Also, for all the PDFs that I’ve imported myself, I’ve spent hours copying-and-pasting the abstracts from America: History & Life into their citations. So between having them in collections and being able to keyword search either the full-text or just the titles + abstracts, tagging becomes less than necessary.
I will have to check this out and see if it is better than my folder and chart system.
Thanks for the article on this! This is nearly the same workflow that I employ. I’m not too fond of Pages, so I stick with Word. (To be fair, I don’t like Word as it’s a bloated mess, but I just haven’t enjoyed Pages. Maybe I’ll give that another shot.)
Papers and Scrivener are wonderful tools.
I hate to come off like a shill or seem as I’m promoting them, but they truly are. In fact, the ability to use both Papers and particularly Scrivener was the primary reason I switched from PC to Mac.
People should also be aware that both Papers2 and Scrivener offer academic discounts.
I’d like to second Michael’s suggestions. This is one productive workflow. With the introduction of “Smart Collections” in Papers, it’s now possible to apply multiple tags to any paper and then have collection folders in the sidebar group any combination of tags together. My tagging scheme allows me to attach several tags to a single entry, for example, “primary source,” “antebellum period,” “American religions,” and “mission” for Enoch Pond’s 1824 _Short Missionary Discourses_. Now that source will appear in each one of those separate collections, and later on, it will show up in any keyword searches I might perform on the whole database that include those tag names.
Dave, I responded to Ken on this topic by saying that between my extensive use of Collections and the full-text/title & abstract search feature, I don’t really feel the need for systematized tags.
This was an interesting read, Michael. I’m always looking to increase the overall productivity of the researching-and-writing process without sacrificing quality, and you seem to have found a way to achieve this and works well (very well?) for you. I’m also designing a workshop for UGs that outlines various methods to research and write and this will definitely be a big hit.
A question, though: how long did it take you (or anyone else who uses them) to get to grips with the two programmes? I’m a massive advocate of Zotero and use it religiously for storing materials (PDFs, backup notes, MS materials &c.). I’m also a fan of Word, which is handy because Zotero has a smashing plugin that inserts references for me. I’ve tried (and am still trying…) to come to grips with Evernote, but I find myself constantly going back to Word for taking notes, writing up &c. because Zotero links in so nicely. I am, however, always looking to improve, and these two programmes have some potential.
(Also, I converted from PC to Mac before going back to PC. One of the few, I’d imagine.)
Back to PC?!!?!? Seriously though both of these apps are now available for PC as well. It took a fair amount of trial-and-error before both working out the customization and the workflow. I spent the time on my 2nd UG honors thesis perfecting it ahead of grad school. That said, I am happy to share my Preference files and templates with anyone interested in using Scrivener.
Yeah! Back to a trusty Lenovo. I went back because Mac’s don’t run MS Access, and that forms an utterly central part of my project. Although Mac’s have their equivalents, I found they just aren’t **the same**
Sure: would love to see how an experienced user sets the app up.
I just got a new iMac to replace my MBP and I installed Parallels and Windows XP on it. You can do the same and run Windows programs right on your Mac.
Just invested in Scrivener 🙂
It’s worth it to take a few minutes to look at the manual and to spend a little bit of time just clicking on stuff and really looking at the menus. Almost every aspect can be customized and you can of course use any feature in the way you think will prove most useful to your specific project. Of course, if you have any questions or (as I mentioned below) if want me to send you my preferences file, just let me know.
Great read. One question, how well does Scrivener handle footnotes and endnotes? Does it work with Zotero?
I still use Zotero + Word, but now that I’m near the end of the diss, I think I might make a change.
Bob, I’m not sure about Scrivener’s integration with Zotero since I don’t use the latter. Also, because Scrivener is not a word processor per se, it handles footnotes in a unique way. They are located on the right sidebar of each document (see pic). It’s nice because you can see all your footnotes at once, but it may take some getting used to for someone used to Word. In terms of exporting the document, you can choose whether you want to export them as footnotes or endnotes (and if you use Pages, you can switch between the two with one click). Also, comments (in yellow) also appear in the right sidebar. So when I send out a draft to people for feedback. I copy-and-paste their comments into Scrivener comments in the corresponding spot. So in one glance, I can see if multiple commenters had a problem with a specific section or idea.
See here http://zotero-odf-scan.github.io/zotero-odf-scan/ for Zotero/Scrivener integration. A longer write-up with screenshots on my blog http://zoteromusings.wordpress.com/2013/05/06/announcing-rtfodf-scan-for-zotero/
I also forgot to mention that I keep my Scrivener project files (basically one file with everything in it, or on Windows a folder) in Dropbox so it syncs in pretty much real time and I never have to worry about losing (in the case of one project) years of work due to hard drive or computer failure. Some people even keep their Papers folder in Dropbox. I just back mine up to an external HD once or twice a month or so. I also forgot to mention that you can set filenaming standards in Papers so that when you import a PDF it gets renamed and put in the Papers folder, so it not only organizes your PDFs in the app but also on your hard drive.
I’ve been using Microsoft OneNote for my digital workflow. It’s come in very handy for organizing class notes, but like most things, there are pluses and minuses. I will definitely be checking out that Pages program you’ve highlighted.
Pingback: Digital Workflow for Historians | Everything Scrivener
Thanks for this informative post. I am ALWAYS open to new ideas to help in my production of historiography. I have liked Papers on my Ipad, though I find the annotating feature pretty clumsy (for all PDFs actually). And I am trying out these 2 new (to me) products. I will say that some of us actually like PCs for their openness and flexibility. Apple is very controlling. And I am impressed you could do anything with Pages which I found maddening due to its lack of features. To each his own, but hopefully Scrivner and Papers will be a good addition.
….to my PC!
I have used both of these apps’ Windows versions. They feel very much like a Mac app transferred to Windows, which may be a good or bad thing depending on the user. I’d be interested to see what you think of them after spending some time with them.
P.S. – The iPad version of Papers is great for reading, but less so for annotation and other tasks. The desktop app handles those things much better.
Pingback: Digital Workflow for Historians | Dan Royles
Pingback: The Junto: Digital Workflow for Historians | Ye Olde Royle Blog
Pingback: What We’re Reading: June 20, 2013 | American Historical Association
May I have some Scrivener advice please?
I’m working on a set of articles but I don’t know where to put the wayward sentences and quotes that seem useful but have not found a home yet. Do you have a suggestion for where to put these without them becoming lost or cluttering up my argument?
Thank you for any thoughts,
Patrick
Patrick, you might try putting them in the yellow Notes section of the document you’re writing. Or you might try creating a folder in the Binder called Notes and putting them on documents there. Or, if you are on a Mac, you might try hitting CMD+SHIFT+RETURN and put them on the Scrivener Scratch Pad. Hope this helps.
Thanks Michael.
I’ll try each of these and see what works best for me. Probably I’ll use the Document Notes section and then remember to check through each notes section when I’m missing something that now has a potential home.
Thanks.
One other way to keep things relevant to a whole project rather than a specific document besides for those mentioned above is to click on where it says DOCUMENT NOTES over the yellow notes section for the document. You will be given a drop-down menu that includes PROJECT NOTES. These you can see while working on any document. So if you don’t want to have to remember where you put certain notes, you can put them in there and they’ll always be available no matter what document you’re working on.
Now that’s brilliant.
The project notes are just right.
Thanks!
Thanks for this post, I hadn’t heard of Papers, which seems useful. Two questions: first, is there a simple way in Scrivner to save your work in a nonproprietary file format? I have a friend who does everything in txt files (not even RTF) to make sure he can access things years later when we’ve all moved on to some new program. I still have a bunch of stuff in WordPerfect files that will likely be unreadable by any program pretty soon. Second, what is it like using Scrivner on a laptop? It looks like all those panels would work best for a big desktop monitor.
I am yet to come across a file type that Scrivener will not import. “Your friend” saving everything as .txt files is being overly paranoid. 😉 WordPerfect stuff should be converted, but Microsoft Word file formats as well as .rtf will likely remain usable for decades. I can’t foresee Microsoft ever coming out with a version of Word that does not support .doc files and certainly not .rtf files, and even if they did, other programs would still be able to open them. WordPerfect files are readable by a number of word processors including OpenOffice which you can then use to save in various formats.
The documents that you open in Scrivener are just .rtf files. You can export any of them as .rtf, .doc, .html., Open Office, or even just .txt. There is nothing proprietary about Scrivener except its Project File which on a Mac is package that holds all the files in the project and on Windows is simply a folder.
As for the experience, I used Scrivener on a 13″ MBP for over 3 years. Recently, I bought a “big desktop.” I’m not going to lie… it’s better on the bigger screen, but not as much as I perhaps thought it would be. A 13″ laptop is certainly not too small to use it.
Reblogged this on Gregory L. Richard and commented:
I absolutely love Scrivener. Scrivener and Zotero were essential to my dissertation.
Pingback: Thinking about Digital Workflow | The History Channel This Is Not...
I have one quick question. Other than Papers’ “collections” and its associated features, what is the difference between Papers and Zotero for instance? I have combined the use of well-organized file structures, Zotero, and Word (disappointedly) to achieve the same ends. But I am intrigued by the automatic file naming as I too have a penchant for downloading slimly relevant pdf’s from Jstor only to have a folder full of oddly named files.
I am in no way an expert, but have experimented some with Zotero. Downloading law review PDFs through HeinOnline, somewhere somehow, this format generated automatically:
Primary Author – Year – Title (truncated if too long).pdf
For example:
Bernstein – 2011 – Lochner and Constitutional Continuity.pdf
Similar was the default format for ZotFile, a utility to mark PDFs on an iPad or Android-based device, and transfer (and sync) them to a Zotero database on another computer:
Bernstein_2011_Lochner and Constitutional Continuity.pdf
Seeing it generated in two different utilities, I started naming all of my PDFs in this format. If a second author were important, and I wanted to see it in a list, I added it. For example:
Alchian_Demsetz_1972_Production, Information Costs, and Economic Organization.pdf
I like how it is alphabetical by author (or easy to alphabetize), contains the year – and simple. The “pdf” at the end is pretty optional for most people. And for me, I didn’t bother to change the ones that automatically had a dash instead of an underline.
Maybe I will standardize everything at some point, but I like the basic information, and order.
Here is the url to a ZotFile webpage,
http://www.columbia.edu/~jpl2136/zotfile.html
You can see the default Wildcards there (in the small picture), %a_%y_%t.
I worked in Zotero today, for the first time in a long time (other than just saving a lot of stuff from around the web, for later use or deletion).
In Zotero, whether news articles or academic articles from JSTOR, when you attach a snapshot (such that it is in your database, and searchable, instead of just a link), the attachment for the snapshot might be named something like “New Republic snapshot,” or from JSTOR, “[a bunch of numbers].pdf”. However, when you open a pop up menu on that snapshot, one of the options is “Rename file from parent metadata.” When selecting that option, I see the new format is exactly like my first entry above:
Bernstein – 2011 – Lochner and Constitutional Continuity.pdf
– or another example –
Barnes – 2013 – Supreme Court stops use of key part of Voting Righ.html
So that is a standard Zotero naming convention (where I got it in the first place).
Another note on JSTOR (and HeinOnline etc.), I am not positive, but I may have had to make a small modification or download in Zotero — which I learned about in Zotero Preferences and from searching Help — such that after I “View PDF” from JSTOR in my browser, and press the download button from there, the three options in the pop up box are: (1) Open in “Preview”, (2) Save file, or (3) Save to Zotero [with a checkbox option her, “Retrieve Metadata for PDF”]. When I save to Zotero directly, or option 3, it creates a main item with the article title and with the snapshot attached, again, named “[a bunch of numbers].pdf”. That is where I rename it via the pop up menu. If, instead of saving it directly in Zotero, I were simply to save it to my hard drive, option 2, it is just going to be titled [a bunch of numbers].pdf, in my Downloads file.
That is a lot of technical detail. The main point is that is a useful naming format.
On a final note, I saved a bunch of PDFs years ago in the Cloud via both Google Documents (now called Google Drive) and Microsoft SkyDrive. I did this both as a permanent backup, and so I didn’t have to transfer these files every time I got a new computer. When I got an iPad, it was amazing (to me) that all of these were suddenly automatically accessible in a beautiful handheld reading device, via the Google Drive and Microsoft SkyDrive apps. Just something else people might consider. Zotero is superior to this now, but it has more of a learning curve. Google has “collections” also (similar to Zotero and Papers), so that is a way to possibly spec some things out, versus just straight storage (as I do in SkyDrive, alphabetically by author).
Pingback: Literaturverwaltung kompakt 5/2013 | Literaturverwaltung
Thanks for your very informative post, Michael.
One thing I like about both Papers and Scrivener is they are integrated packages. I downloaded the trial versions and tried them out. Scrivener I think I will use right away to write longer documents. There are things I like about Papers, but for my own purposes, I see that Zotero is better for me, for now. Some of what I do is at the intersection of economics, law, and history. A lot in economics and law is available online for free (e.g., Online Library of Liberty, Federalist Papers, court cases). Not all of that, but some I will want to pull in a webpage (like a chapter from a book) to search the entire text. Some I will just link to. On web pages, unlike PDFs, it looks to me like Papers currently just saves the link. Being still new to Zotero, using it more also will help me become more of an expert.
But Papers, like Scrivener, looks very user friendly. They fit together well.
Just FYI, you can open browser windows in Papers and save URLs just like any other citation.
Thanks, Michael. I knew that, but maybe wasn’t clear. Papers is very useful in that respect, and I like how the web pages are in tabs, a convenient workspace there. I seriously considered using Papers (and may yet). For example, I don’t necessarily have to have every Supreme Court case I want ready access to, physically in my database. In fact, it is easy to copy the syllabus from Justia into the abstract (which may work about as well).
But my point here, the distinction I wanted to make, is that I think in Zotero, when you take a snapshot of a web page (versus just the link), the text is indexed and therefore part of a search.
This functionality, if I understand it correctly in Zotero, could be more important for me with old economics texts. Maybe everywhere I might find a web page to a chapter, for example, in The Wealth of Nations, I might also find a PDF. It is more convenient for me to take a snapshot of the webpage. I could copy the entire PDF into Zotero instead, but the size of the database will grow, and might ultimately slow more than I’d prefer. Instead of adding a PDF for entire book to the database, I could view it in Preview, and cut out what I don’t want. But that is a lot more work than just adding an entire chapter from a webpage. On many of these old economic texts, they are freely available online, chapter by chapter.
As you point out though, I can link the URLs in Papers, as I can in Zotero. Using Zotero some has helped me better decide what to link, and what I want copied.
Much of this though is yet to be determined. 🙂
Thanks again. This is all pretty technical, and potentially misunderstood in a blog post.
Hi, Michael. One quick question: when you import files from Papers to Scrivener, do you import them directly or as aliases? One advantage of doing the former is you can import virtually everything, but you cannot keep these imported files in sync with those in Papers. From the screenshot, it seems that this is what you do. If you make changes in those imported files such as making more annotations, what will you do to keep all of them in sync?
You are right. I don’t do aliases, mostly for backup purposes. I tend to periodically copy notes from Scrivener into Papers, which is not the most ideal way of doing it. If I annotate a document heavily (i.e., highlighting), I will just replace the version in Papers with the one from Scrivener. The changes you make to PDFs, like highlighting, aren’t actually saved to the document itself until you export it from Scrivener. So I export it and then add it to the Papers entry. I think what you’ve pointed out is the least convenient aspect of using both applications and I would, of course, love to see the developers come up with something that allows this. I think Scrivener at some point will have to update the way it handles files (esp. file naming) and perhaps then it will be possible to sync the two. Until then, one has to do it manually.
Pingback: Leaving Paper Behind | Dr Stephen Robertson
Great post! I have a question about Papers. Once you download the software, does it automatically index your hard drive for all available pdfs, or do you have to import them manually? Thanks!
Herbie, it does not. It will move them all into one place and rename them with a convention you decide, however. And of course if you choose to select the entire drive to import, I guess it’d be the same thing as what you’re talking about.
Another useful tool with functionality similar to Papers is Mendeley. It does a great job of organizing large libraries of PDFs and has the advantage of being free. Great article. Cheers.
I think I might be one of the last grad students on earth who still has not switched to citation management software.
First of all, I have enjoyed and have been enlightened by the above essay & the following discussion. Nevertheless, as a narrative historian, I need a way to get as close to everything I have taken notes on as I can. Sources vary in style, terminology, and the facts & opinions cited by authors of secondary & primary documents. I used to use Apple Works which was very flexible — I deeply resent having to classify the events that I study as to type before I’ve written the text. Apple Works allowed me to quote sources at length from my notes, assign a date & a place to an event, and perhaps a tentative category. It also allows me to highlight themes & keywords. I am fully able to connect material and stories without classifying them in strict categories in advance. At the same time, I’m able to keep my notes entirely under one very useful program.
It seems to me that most historical data bases concentrate on pure data, i.e., information boiled down to quantitative facts. I admit such data is useful, but it can severely corrupt our understanding of human history, which was traditionally a field based on stories. In other words, Apple Works was a decidedly flexible format that allowed me to compose notes differently, depending on the categories I tentatively assign to them. The Czars at Apple, however, decided that this easy method was no longer needed.
For the present, the majority of my files which number in the thousands, are stored in one very fragile old computer. For the new files, I have simply put my new notes in paragraphs on a word processing file; these notes are composed somewhat like the notes I described above. This works, but I am not able to alphabetize the notes, a function I often find useful.
What I’m looking for is a data base that operates much like Apple Works, in which there are few rules about how to compose notes and when to retrieve them.
The methods used in the above article are useful, but they allow for little creativity. In addition, such data bases appear to take up too much time that could be used in writing. I sometimes feel compelled to tell my fellow historians that our connection to the social sciences is at best tenuous. Our profession is, in the end, based upon that most ancient way in which humans conveyed culture — through the art of story telling. Despite our advances into the age of technology, we should not forget that we are essentially story tellers.
In any case, I would very much like to know if any other historians feel the same as I do and if anyone is working on databases that allow for creativity.
Both the essayists and the commentators on this page are to be commended for their efforts in a quest for assistance in our peculiar scholarly endeavors that range from such efforts as data analysis and simple stories. To say the least, we are a bit quirky. It seems to me that the databases we use should be as open-ended as we are.
William, the limitations you are describing seem to only apply to Papers not Scrivener. What you are describing is exactly what Scrivener allows you to do. The first app, Papers, is for cataloguing PDFs and references. The second, Scrivener, allows you to compile and organize sources of all kinds any way you want. It also has extensive tagging and labeling. Scrivener was created for novelists and screenwriters and it would certainly lend itself to narrative history even more than to the kind of history you see in the screenshots above.
Thank you. I intend to look more carefully at Scrivener.
Can I also recommend that you take a look at DEVONthink Office Pro (and it’s other versions). It has very clever associations that it builds between pieces of text. Perhaps this is earlier in the research process that what you’re talking about. However, I’ll let Steven Johnson explain it to you:
http://www.stevenberlinjohnson.com/movabletype/archives/000230.html
DevonThink Pro was one of the apps I used while formulating my workflow. It’s excellent for storing and recalling files but I decided that I needed that kind of thing less overall than I did for each project. And with Scrivener’s writing capabilities, it made more sense to me. Of course, developing your own workflow is a subjective process and for some they might find using DevonThink instead of something like Papers makes more sense to them (that is, if they then add another separate reference manager to their workflow).
My apologies for my previous comment. I forgot which thread this was that I was looking at. The links may still be useful though.
Pingback: Trials and Tribulations of Writing while Sleeping « The Junto
This is really interesting, You are an overly professional blogger.
I’ve joined your rss feed and sit up for looking for more of your wonderful post.
Additionally, I have shared your web site in my social networks
My many liked style regarding artwork is practical and realistic and, lately, a surrealistic
bent, for example, in my Allegorical paintings.
Pingback: Organizing your Research & Workflow | Zoe Genevieve LeBlanc
Pingback: Dissertating with Scrivener « The Junto
Pingback: My own personal card file!
Hey there! I can’t find anywhere the template or how to get it and I could really use that right about now! Can anyone direct me on where to go?